rabbitmq自带内建集群,其旨在rabbitmq的高可用,允许消费者和生产者在rabbitmq节点崩溃的情况下继续运行,以及通过添加更多节点的方式来线性扩展消息的吞吐量。但是即便是将消息、队列、交换器设置成可持久化,当集群中的一个节点挂掉后,该节点上队列中的消息也会消失,因为在默认情况下rabbitmq是不会将队列的内容复制到整个集群中(除非进行特别的设置:镜像队列)。
这里不会对rabbitmq集群做深入探讨,是对集群的关键信息做出总结,想了解详细的集群方面的指引可查看官方文档。
集群中的元数据
集群模式下包括如下元数据:
- 队列元数据:队列名及其属性(是否持久化、可删除等)
- 交换器元数据:交换器名称、类型及其属性(可持久等)
- 绑定元数据:路由绑定表
- vhost元数据:为内部信息(队列、绑定、交换器)提供命名空间和安全属性
- 集群节点的位置,及节点与上述元数据的关系。
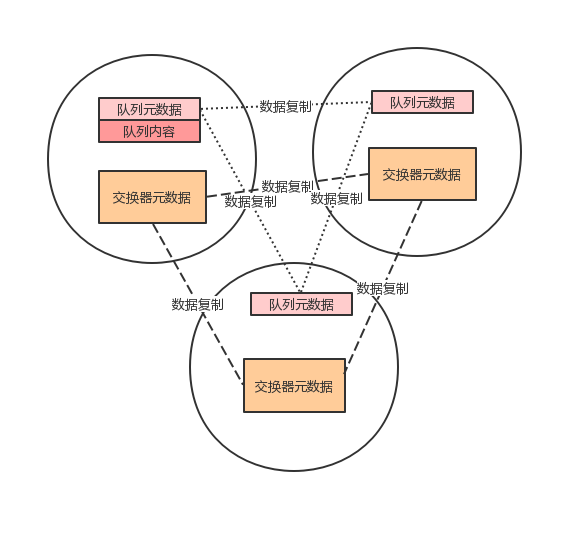
集群中的队列
在集群中,队列的所有信息(元数据、状态、内容)是有队列的创建节点持有,而其他节点只是拥有队列的元数据和指向队列所有者节点的指针。这样的设计是考虑到两个因数:
- 存储空间:状态和内容的拷贝是很占空间的,造成大容量数据冗余,浪费存储;
- 性能:集群内数据的复制会影响性能,如果冗余拷贝的是可持久化的消息,其还会与硬盘有IO,那么性能将倍受影响;
而这样的设计又会导致一个情况,即当一个队列的持有这挂掉之后,该节点上的队列和关联的绑定信息就在集群中蒸发,队列的消费者将丢失订阅,生产者生产的消息将消失。如果消失的队列是持久化的队列,那么便在恢复后可以恢复数据信息,在重新进入集群之前,另外的节点重新声明创建队列是不可行的,会被告知“404 NOT FOUND”。
集群中的交换器
交换器实际上是一个虚构的概念,并不是想队列那样实际存在,其为一个名称和队列绑定的查询表,当消息被发布到交换器的时候,消息是在信道中根据路由键去和绑定列表进行比较来路由消息到相关队列。由于交换器是指一个查询表,并不占空间,所以在集群中的每一个节点上都会有一份交换器的信息。
集群中的队列和交换器的数据情况如下图所示:
集群节点(内存节点/磁盘节点)
每个rabbitmq节点,在集群中有且仅可能为内存节点和磁盘节点(单节点默认为磁盘节点),其中内存节点是将所持有的信息(队列、交换器、绑定、用户、权限和vhost等的元数据)存储在内存中,而磁盘节点是将其存储在磁盘上。
磁盘节点好理解,因为需要持久化元数据信息;而内存节点呢?当然是为了减少整个集群的磁盘IO,因为每个节点上的元数据其实是一样的,那么只要有一个是磁盘节点,就不会出现元数据丢失情况,这样即提高性能又可保障数据信息。
所以一个rabbitmq集群,至少有一个磁盘节点,而如果仅有一个磁盘节点的情况下会出现一个情况:仅有的磁盘节点挂掉后虽然集群可正常运行,但集群便无法创建队列、交换器、绑定,以及添加用户、更改权限和几点的增删操作了。所以,为了集群的高可用,应该至少设置两个磁盘节点,虽然两个磁盘节点都挂掉会出现同样的情况,但至少比一个更可靠。而在内存节点的创建时,需要告知磁盘节点,以便其从磁盘节点复制集群的元数据信息。
集群节点升级
集群节点升级,即升级rabbitmq的版本,这里建议过程如下:
- 备份集群配置;
- 关闭所有生产者,等待集群现有队列中的消息被消费完毕;
- 关闭所有节点;
- 选择一个磁盘节点优先升级(持久化集群数据);
- 其他其他磁盘节点;
- 启动内存节点;
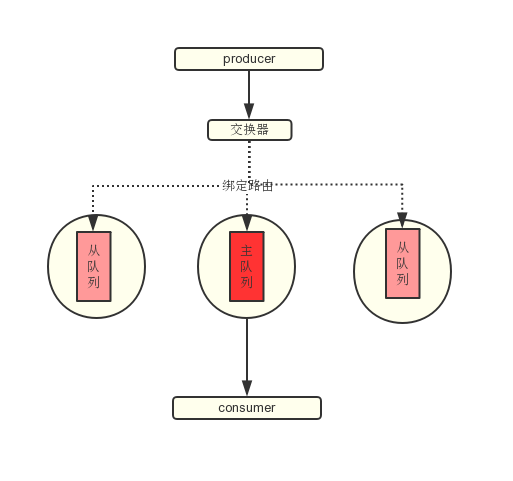
镜像队列
前面说道的集群中某节点挂掉后,该节点所持有的队列的状态和消息内容将消失的情况,并非无解决版本,rabbitmq在后续版本中提出了镜像队列的概念:主从冗余。镜像队列的住拷贝亦只会存在一个节点上,及为主队列(master),其他节点上该队列的拷贝均为从队列(slave),一旦主队列所在的节点挂掉,最老的从队列将被选举为新的主队列。镜像队列的声明简单,比创建普通队列多了一些参数,如 x-ha-policy 。
有关镜像队列详细说明可见官方文档
镜像队列的路由和普通队列差异不打,只是当信到将消息路由到一个队列后,还会将消息投递到该队列的所有slave队列。我们可以把镜像队列的消息路由想象成交换器的fanout模式,如下图所示: